
El escenario de la actual pandemia es el caldo de cultivo perfecto para todo tipo de negacionismos y teorías de la conspiración. Sin embargo, a poco se aplique la lógica más básica, es fácil comprobar cómo muchas de estas teorías apenas sí tienen recorrido.
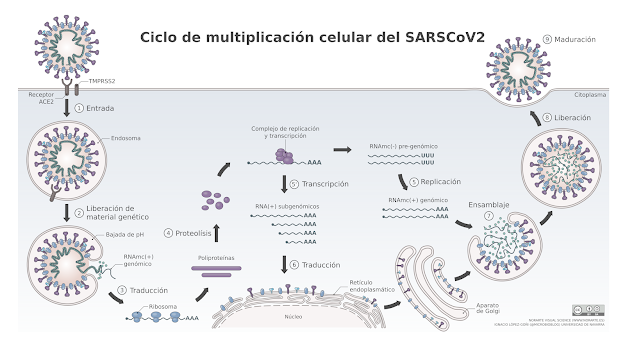 |
| Arriba representación esquemática del ciclo de infección del SARS-CoV-2. Desde el punto de vista del combate contra la enfermedad, la parte más importante del proceso es el momento en el que el virus penetra en la célula vía dos proteínas de membrana que “le abren el paso” (identificadas como TMPRSS2 y ACE2). Bloqueando esta fase inicial el virus no puede infectar a las células y, por tanto, queda a merced del sistema inmunológico, que procede a su eliminación. Fuente: microBIO. |
El pasado 17 de abril, hace ya un tiempo de esto, una impactante noticia saltaba a los titulares en todo el mundo. En un canal de televisión francés el profesor Luc Montagnier, galardonado en 2008 con el premio Nobel de Medicina por su descubrimiento del Virus de Inmunodeficiencia Humana (VIH, tristemente célebre por ser el causante de la enfermedad que conocemos como SIDA), hacía saltar la bomba informativa. Según declaraba el SARS-CoV-2 podría haber sido diseñado en un laboratorio mezclando material genético del VIH con el de un coronavirus de murciélago, para que así este último infectara a humanos. “No es natural. Es un trabajo de profesionales, de biólogos moleculares. Un trabajo muy meticuloso”, aseguraba, haciendo referencia a un trabajo publicado en febrero y que afirmaba que en el código genético del nuevo coronavirus había inserciones de material procedente del VIH. Más allá de que ese trabajo no fuera más que un preprint, es decir, un estudio que no había superado la necesaria revisión por pares y que posteriormente fue retirado, las declaraciones de Montagnier tuvieron una evidente repercusión y alimentaban la teoría de la conspiración de una posible “conexión China”, cuyo epicentro estaría en el ya famoso laboratorio microbiológico de Wuhan, ciudad que pasará a la Historia por ser el primer foco identificado de la pandemia.
La vorágine de los acontecimientos parece haberse llevado por delante los polémicos comentarios del eminente investigador, ya retirado. Tampoco debemos olvidarnos del hecho de que buena parte de sus ex colegas en el Instituto Pasteur de París, entre ellos el también reputado virólogo y especialista en genómica evolutiva Etienne Simon-Lorière, aseguraran que esas afirmaciones “no tenían ningún sentido”. Realmente la presunta teoría de la hibridación artificial entre el coronavirus de murciélago y el VIH tuvo una vida cortísima, pues el mismo mes de febrero ya se público otro estudio que la desmontaba (ver aquí el artículo) y que sí superó la revisión por pares ¿Nos olvidamos de las teorías de la conspiración que insisten en eso de que el nuevo coronavirus se creó en un laboratorio chino o, en su defecto, en cualquier otra parte? Sólo hay que realizar un breve paseo por Internet para descubrir que no. Señalar a China como la responsable de haber creado un arma biológica bajo la forma del SARS-CoV-2, ha sido un discurso reiterado por parte de la administración Trump con el objeto de desviar la atención de su desastrosa gestión de la crisis. En ese sentido noticias como la de una viróloga de Hong Kong que ha huido a Estados Unidos, asegurando que Beijing ocultó la amenaza de forma deliberada durante mucho más tiempo de lo que se piensa, alimentan todavía más el rumor “conspiranoico” que hace sospechar que el nuevo coronavirus podría no tener un origen natural. También en espacios televisivos de gran audiencia como Cuarto Milenio se prodigan expertos militares que, mencionando la citada noticia, dan pábulo a esta posibilidad. En uno u otro caso quienes realizan tales afirmaciones no lo hacen de forma desinteresada, en lo que respecta actual inquilino de la Casa Blanca (quizá por poco tiempo) la intencionalidad política está muy clara, pero nada de eso tiene que ver en realidad con la Ciencia.
¿Hay pruebas de que el SARS-CoV-2 fue creado en un laboratorio y escapara de allí o fuera liberado intencionadamente? Salvo ciertas voces discordantes y un tanto excéntricas, como es el caso de Montagnier, la comunidad científica asegura que ninguna sostenible. Pero esto no nos lo tenemos que creer simplemente porque sí y, para eso, es necesario explicar las cosas debidamente. A continuación trataré de hacerlo yendo por partes y basándome, como no podía ser de otra manera, en trabajos y declaraciones de expertos en virología y biología molecular. Antes de eso sin embargo conviene tener claros una serie de conceptos esenciales.
Para empezar un poco de biología molecular
La biología molecular es, como su propio nombre indica, la rama de la ciencia que estudia a los seres vivos desde un punto de vista molecular. Es decir, estudia los procesos que tienen lugar en el interior de los organismos a la escala de las principales macromoléculas que participan en ellos, a saber, los ácidos nucleicos y las proteínas. Para resumir de la forma más sencilla posible, los ácidos nucleicos serían algo así como el “manual de instrucciones” a partir del cual las células pueden fabricar las proteínas, mientras que estas últimas serían en cierta forma los “ladrillos” con los están hechas las propias células. A estos materiales de construcción debemos añadir un segundo grupo de proteínas extremadamente importantes para la vida, las enzimas, algo así como unas extraordinarias nanomáquinas que actúan a nivel intracelular y que hacen posible todas las reacciones químicas necesarias para la vida (son catalizadores de dichas reacciones). Además de estos dos grupos principales, proteínas estructurales y enzimáticas, existen en los seres vivos otros tipos de nanomáquinas que realizan las más diversas funciones. Tenemos proteínas reguladoras, que actúan como hormonas y mantienen la homeostasis del organismo (como por ejemplo la insulina); proteínas transportadoras, que son como “vehículos” que trasportan sustancias de unos lugares a otros (como la hemoglobina de la sangre); proteínas receptoras, situadas en las membranas de las células, que actúan o bien como “guardianes” que permiten o impiden el paso, o bien como “antenas” que reciben señales que luego desencadenan algún tipo de respuesta a nivel intracelular; proteínas motoras que actúan como “motores” o estaciones de bombeo minúsculas y, ya por último, proteínas defensivas, como los conocidos anticuerpos, destinados a localizar y señalar para su destrucción a los agentes extraños que invaden el organismo. Aparte de todas estas asombrosas nanomáquinas existen también las llamadas proteínas de reserva (como la caseína de la leche), que no son más que simples depósitos de almacenamiento de energía de los que los organismos se sirven cuando lo necesitan.
Así pues las instrucciones de ensamblado guardadas en los ácidos nucleicos bajo la forma de información genética, les sirven a los seres vivos para fabricar todos los tipos de proteínas que hemos visto. Desde los ladrillos que constituyen el cuerpo del edificio celular, hasta la gran variedad de nanomáquinas que “trabajan” dentro de dicho edificio y lo mantienen en funcionamiento (catalizadores de reacciones, vehículos de trasporte, antenas receptoras de señales, guardianes en las distintas “entradas” a la célula, etcétera). El proceso mediante el que esa información pasa a convertirse en proteínas funcionales se denomina expresión génica, la base misma mediante la cual la vida se sostiene a sí misma. El elemento fundamental de dicha expresión es el llamado código genético, único de cada organismo, que no es otra cosa que el lenguaje en el que toda esta información está codificada. Así el lenguaje de los ácidos nucleicos es, en esencia, el lenguaje de la vida.
 |
| En la imagen representación esquemática de los dos tipos principales de ácidos nucleicos. El más conocido ADN con su característica doble hélice y el ARN, una hebra simple. Fuente: lopezdearenas.org |
¿En qué consiste dicho código? Básicamente en una secuencia, única para cada organismo como hemos dicho, de lo que podríamos denominar “letras”, que es el lenguaje en el que se expresa toda esa información. Estas “letras” son un tipo específico de moléculas llamadas bases nitrogenadas, que van ensambladas unas detrás de otras en largas cadenas cuyo esqueleto básico se compone de azúcares (llamados pentosas) unidos a grupos fosfato. Dicho de otro modo, estos polímeros de azúcar-fosfato son el soporte invariable donde van fijadas las “letras” del código genético. La forma que tenemos de representar ese código es en base a una serie de mayúsculas, que no son otra cosa que las iniciales de las bases nitrogenadas: A para la adenina, T para la timina, C para la citosina, G para la guanina y U para el uracilo. Así, a modo de ejemplo, una breve secuencia genética cualquiera se puede representar como ATTCGCCTATAGC. Es posible que muchos hayáis visto en algún sitio secuencias de letras así representando información genética.
Ahora bien, hay dos tipos fundamentales de ácidos nucleicos, el ácido desoxirribonucleico o ADN (que tiene una desoxirribosa como azúcar en su esqueleto fijo y emplea la timina -T- como una de sus letras) y el ácido ribonucleico o ARN (que tiene a la ribosa como azúcar y emplea en cambio el uracilo -U- como una de sus letras). Todos los organismos guardan a buen recaudo en el interior de sus células el “libro de instrucciones” de su código genético para fabricar proteínas, en muchos casos dentro de una especie de “fortaleza” conocida como núcleo celular (en el caso de animales, plantas y hongos, que no en el de las bacterias). Es ahí donde permanece empaquetado el ADN, que no es otra cosa que una especie de copia de seguridad, donde la información viene además duplicada en una doble hebra de secuencias complementarias, en la que la A siempre se empareja con la T y la C con la G. Así las letras se agrupan de tres en tres formando “palabras” denominadas codógenos, muchos de los cuales constituyen la secuencia que porta la información para sintetizar una proteína determinada. A dicha secuencia la llamamos gen y, el conjunto de todos los genes que se expresan en un organismo, recibe el nombre de genoma. También hay que tener en cuenta que a veces ocurre que, durante el proceso de realizar copias del libro de instrucciones del genoma, se producen errores y algunas “letras” o “palabras” se trascriben mal, alterando la información de origen. A ese fenómeno lo llamamos mutación y muchas veces no tiene efecto alguno, si bien en otras es dañino e incluso puede darse el caso de que conduzca a la aparición de alguna característica deseable.
¿Cómo pasa a convertirse la información de la copia de seguridad del ADN en proteínas? Mediante unos intermediarios o “mensajeros”, en este caso moléculas de ARN, que salen del núcleo con las instrucciones para sintetizar las proteínas que la célula precisa en cada momento. Este ARN mensajero (pues ése es su nombre) sería algo así como un fax o correo electrónico con una orden de producción, enviado desde el centro de mando celular a unas fábricas denominadas ribosomas, donde las proteínas son sintetizadas a partir de unas moléculas llamadas aminoácidos, los componentes que, ensamblados unos detrás de otros, forman las largas cadenas de las que se componen las proteínas. Únicamente 20 aminoácidos se combinan de todas las formas imaginables para constituir la casi infinita variedad de proteínas presentes en los seres vivos. De esta manera se produce la expresión génica. El triplete de bases del codógeno de ADN se traduce a un triplete complementario de ARN mensajero (donde U sustituye a T) que, para simplificar, termina traducido en su aminoácido correspondiente (por ejemplo, los tripletes AAA y AAG codifican para el aminoácido lisina). Este fascinante proceso es realmente complejo pero, a grandes rasgos, funciona de esta manera. Las proteínas salen de esas plantas de fabricación que son los ribosomas “inmaduras”, es decir, como simples hebras de aminoácidos engarzados en largas secuencias. Pero las cargas eléctricas de estas moléculas hacen que las hebras se auto organicen plegándose en estructuras tridimensionales únicas. Así terminan convertidas en los “ladrillos” o las distintas “piezas” y componentes que forman las nanomáquinas de las que hemos hablado, que constituyen o hacen funcionar nuestras células.
Ahora bien, el prodigioso proceso de la expresión génica puede ser pirateado por los virus. Podríamos decir que éstos son algo así como un comando terrorista, que se infiltra sigilosamente en el interior de una célula y asalta la fortaleza del núcleo, para una vez allí “secuestrar” la maquinaria destinada a enviar las órdenes de fabricación a los ribosomas. De esta manera las únicas instrucciones que saldrán del núcleo bajo la forma de ARN mensajero serán las de fabricación de proteínas de virus, con lo que todo el sistema colapsa. La célula así secuestrada se convierte en un gran complejo de fabricación de virus, quedando destruida en el proceso, hasta que al fin los patógenos ya ensamblados y maduros se abren paso a través de las ruinas de su víctima y quedan libres para repetir el proceso en otras células vecinas. Así es como se extiende la infección dentro de nuestros organismos y, para ello, sólo es necesario que un único virus alcance el núcleo de alguna célula. En condiciones normales nuestro sistema inmunológico “reconoce” a estos insidiosos enemigos y los marca con anticuerpos para su destrucción antes de que puedan hacer un gran daño. Pero cuando un nuevo agente aparece dentro de nuestro cuerpo, como es el caso del SARS-CoV-2, las defensas no han aprendido todavía a reconocer la amenaza, por lo que el virus puede actuar con total libertad.
Y ahora el porqué el nuevo coronavirus no ha sido fabricado en un laboratorio
Ya sabemos un poco mejor cómo funciona todo el asunto a nivel molecular y, de esta manera, podremos responder mejor a la pregunta de sí el SARS-Cov-2 procede o no de un laboratorio (ya sea chino o de otro lugar). Lo primero que debemos cuestionarnos es, ¿se puede crear un virus en un laboratorio? La respuesta es por supuesto que sí y, además, es algo usual. Sin embargo no debemos alarmarnos, ni empezar a pensar de inmediato en conspiraciones gubernamentales o malvadas corporaciones que pretenden fabricar ejércitos de zombis. Esto es algo que se hace rutinariamente en investigación, trabajar con virus para conocerlos mejor o desarrollar todo tipo de herramientas biotecnológicas. De hecho, la famosa vacuna que están desarrollando conjuntamente la universidad de Oxford y la farmacéutica AstraZeneca es, en esencia, un virus modificado en el laboratorio que recibe el engorroso nombre de ChAdOx1 nCoV-19. Lo que han hecho los investigadores es tomar un virus que produce el resfriado común en chimpancés, eliminando ciertas secuencias de su material genético para que no pudiera infectar a humanos, y añadiendo otras procedentes del SARS-CoV-2. Concretamente estamos hablando de los genes que codifican para la síntesis de la proteína espicular o S (de spike en inglés), algo así como la “llave” que el virus emplea para abrir la “cerradura” que le permite entrar en nuestras células (dicha cerradura es una proteína receptora de membrana llamada ACE2). De esta manera las defensas aprenden a reconocer la “llave del virus” y, en caso de detectarla, desencadenan la correspondiente respuesta inmune. Así funcionan las vacunas. De la misma manera que los ejércitos realizan maniobras que simulan escenarios de combate reales para preparar a sus soldados, podemos “entrenar” a nuestro sistema inmunológico usando algo que se parezca mucho al patógeno que deseamos combatir, si bien lo suficientemente atenuado como para que no entrañe peligrosidad. Una vez entrenadas con estos “virus sparring” inyectados en forma de vacuna, nuestras defensas ya saben cómo actuar al presentarse la amenaza real.
Y aquí es donde viene una de las preguntas clave ¿Cómo creamos material genético quimérico, es decir, mezclamos secuencias de organismos distintos para dar vida a nuestro “monstruo” particular? Virus como el VIH o el SARS-CoV-2 poseen ARN, en vez de ADN, como material genético (o dicho de otra manera, carecen de “copia de seguridad” de sus instrucciones de ensamblado); aparte de que, como todos los virus, no se los puede considerar realmente organismos vivos, pues no pueden realizar por sí solos prácticamente ninguna de las funciones propias de un ser vivo. Independientemente de esta última circunstancia, el proceso para crear ADN o ARN quimérico se basa en cortar y empalmar unas secuencias con otras ¿Cómo hacemos eso? Naturalmente no usando tijeras y pegamento, sino mediante una clase específica de esas prodigiosas nanomáquinas que son las proteínas, así denominadas enzimas de restricción o nucleasas (para cortar) y ligasas (para pegar). Unas y otras cortan o empalman las largas cadenas de ácidos nucleicos en puntos específicos, es decir, reconocen pequeñas secuencias de bases particulares y actúan específicamente en ese lugar para efectuar el corte o el empalme. En el caso de las enzimas de restricción estas secuencias específicas reciben el nombre de dianas de restricción.
 |
| Arriba ejemplo de cómo actúan dos tipos distintos de enzimas de restricción. En ambos casos reconocen secuencias de bases específicas, cortando extremos romos o cohesivos. Son estos últimos los de mayor interés a la hora de crear lo que se conoce como ADN recombinante. Fuente: educ.ar. |
Así es como podemos crear el material quimérico, como por ejemplo ADN recombinante. Y es ahí donde entroncamos con la supuesta creación del nuevo coronavirus en un laboratorio. De haber sido así el genoma del patógeno presentaría huellas de su origen quimérico, a saber, secuencias de bases características que evidenciarían ser puntos de empalme de materiales genéticos de orígenes distintos. Es decir, allí donde actuaron las enzimas de restricción primero y las ligasas después. En los laboratorios los investigadores suelen emplear enzimas procedentes de microorganismos como bacterias, que se cultivan a escala industrial para purificar y después comercializar estas valiosas herramientas biotecnológicas. Es por eso que no es complicado reconocer el trabajo realizado por las enzimas en una secuencia de ADN o ARN, puesto que todos los investigadores trabajan con ellas e identificarían de inmediato si se han usado o no para sintetizar material recombinante.
 |
| Arriba árbol genealógico de los coronavirus. Como se puede observar el nuevo coronavirus (identificado aquí como 2019-nCoV) está estrechamente relacionado con sus parientes presentes en murciélagos. Fuente: Genomic characterisation and epimedemiology of 2019 novel coronavirus. |
N.S.B.L.D.