
こんにちは、![]() id:kouki_danです。はてなではスマートフォンアプリエンジニアとして働いていますが、今回の記事はアプリ利用にともなうアクセス解析がテーマです。
id:kouki_danです。はてなではスマートフォンアプリエンジニアとして働いていますが、今回の記事はアプリ利用にともなうアクセス解析がテーマです。
Firebase AnalyticsやGA4を使っている方は多いと思います。無料で大量のイベントを記録できて便利な一方、以前のGoogle Analyticsであるユニバーサルアナリティクスに比べると、分析クエリの柔軟性に難があります。以前のように分析するにはBigQueryが必要になり、SQLでデータを取り出す必要があります。
Firebase AnalyticsをBigQueryで分析するときに、単にSQLを知っているだけではつまずくことが多いと感じています。料金体系の不安や、時系列で分割されたテーブルの扱い、ネストしたカラムの扱いなど、特有の事情がいくつかあります。
このエントリでは、SQLは分かるけれどBigQueryもFirebase Analyticsもよく分からない人向けに、最初に参照できる便利なテクニックをまとめてみました! この記事を読んでもらえることで、「BigQueryやってみたいけど何となく怖い」という状態を解消し、最初のクエリを記述する手助けになることができればと思います。
クエリの料金を節約するテクニック
Firebase Analyticsではイベントの記録は無料ですが、BigQueryへエクスポートした後のストレージとクエリにかかる費用は有料です。特にクエリにかかる費用は読み込みデータ量に応じてかかってきます。費用はリージョンにもよりますが、2021年8月時点で、1Tの読み込みごとに約5ドルです。
SQLワークスペースでクエリを記述すると、右上に見積もりの容量が表示されるので、これを確認して費用の見積もりをすることができます。

この画像の場合は、13.5Gの予測です。1Tは1,000Gのため、0.0135Tの容量、約7セントの費用がかかることが分かります。ワークスペース上でクエリを実行する場合は実行ボタンを押す前に見積もりを確認する癖をつけておくと良いでしょう。
SELECT *を利用しない
BigQueryの費用は、読み込んだデータ量に対してかかります。BigQueryは仕組み上、対象となるデータを全て読み込んで処理を行います。そのため、どれだけ読み込むデータ量を減らせるか、といった考え方が大切になります。
基本的には、BigQueryのWHERE句での絞り込みはデータを読み込んだ後に行われるため*1、費用には影響しません。LIMIT句も同様です。
SELECT *は全ての列を表示できる便利な記法ですが、一方で全ての列のデータを読み込みます。必要のない列を読み込まないように、個別のカラムを指定すると、それに応じてデータ量を削減できます。
先ほどのクエリを、Firebase Analyticsでよく使用するであろう列のみ(event_name, user_id, event_timestamp)に絞り込んだ結果、もともとは13.5Gの見積もりだったものが、次のように619.4Mまで削減できました。
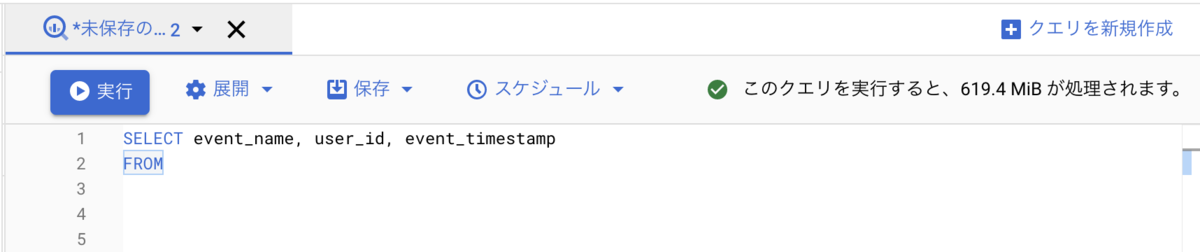
1Gは1,000Mなので、SELECT *を使うケースに比べて1/20の費用に抑えることができます。
なお、全てのカラムを確認したいときには、代わりにテーブルにあるプレビュー機能を活用すると良いでしょう。
頻繁に使用するデータはサマリーテーブルを用意する
次もデータ量を削減する方法です。Firebase AnalyticsのデータはBigQueryに日付ごとに分割されたテーブルとして配置されます。1つのテーブルには1日分全てのイベントが入っていて、さまざまな分析はここから始まることになります。
一方で、よく分析するパターンも存在していると思います。例えば特定のイベントのみを抽出したり、特定のユーザー属性を持っている人のみを抽出したい場合などです。
SELECT *を利用しないテクニックにもつながりますが、よく分析するパターンで全てのカラムを必要としていないときには、サマリーテーブルを作っておくことにより、読み込むデータ量を減らすことができます。
例えば、登録済みのユーザーに対するPVに関係するイベントのみを抽出したサマリーテーブルを作成するクエリは、以下のようになります。
CREATE OR REPLACE TABLE summary.summary_screen_view_registered_user OPTIONS() AS SELECT (SELECT value.string_value FROM UNNEST(event_params) WHERE key = "firebase_screen") AS screen_name, user_id, event_timestamp, FROM `[project].analytics_[id].events_[date]` WHERE user_id IS NOT NULL AND event_name = "screen_view"
また、頻繁に利用する場合は、クエリのスケジューリングを行って、サマリーテーブルを毎日作成できます。

定額料金を検討する
ここまではオンデマンド料金について説明してきました。オンデマンド料金の場合はデータ読み込み量への課金ですが、BigQueryには料金体系がもう1つあります。それは定額料金で、月額や年額でスロットと呼ばれる仮想の計算量を購入します。
定額料金には3種類あり、それぞれの特徴は2021年8月現在で以下の通りです。
| Flex Slots | 月額 | 年額 | |
|---|---|---|---|
| 最低コミット期間 | 60秒 | 30日 | 365日 |
| 費用(米国1ヶ月あたり) | $2,920/100slots | $2,000/100slots | $1,700/100slots |
それぞれのスロットは100スロット単位で購入でき、最低コミット期間が長いほど割引があります。ある時間帯に発行クエリ量多い場合は、その時間帯にFlex Slotsを購入することでコスト削減が期待できる可能性があります。
オンデマンド料金ではプロジェクトごとに2,000スロット使用できます。場合によってはバーストし、それ以上のスロットが割り当てられることもあると説明されています。少ないスロット量だとクエリの実行時間が長くなってしまう可能性もあるので、場合によって使い分けるようにしましょう。こちらのブログも参考になります。
データを整形するテクニック
大量のイベントから自分の必要なデータを作り出すことが、BigQueryで分析する醍醐味です。SQLの詳細については説明を省きますが、Firebase Analytics特有のテクニックについて解説していきます。
_TABLE_SUFFIX を使ってデータを絞り込む
Firebase AnalyticsからBigQueryにエクスポートされたテーブルは、日付ごとに分割されて格納されています。とはいえ複数の日付にまたがるクエリを記述したいことはよくあります。その時に使えるのが、_TABLE_SUFFIXによる複数テーブルを対象にしたクエリです。
例えば、2021年8月のイベント全てに対するクエリを発行したい場合は、以下のようになります。
SELECT event_name, user_id, event_timestamp, FROM `[project].analytics_[id].events_*` WHERE _TABLE_SUFFIX BETWEEN "20210801" AND "20210831"
大切なのは、FROMとWHEREです。FROMでは、日付部分をevents_*としてワイルドカードで指定します。これにより、ワイルドカード部分に任意の文字列が入るテーブル全てが選択されます。ただし、これから説明する_TABLE_SUFFIXなしでクエリを発行してしまうと、膨大なデータ量を読み込んでしまい、それに応じた課金が発生してしまうので注意してください。
FROMのワイルドカードで読み込んだテーブルを、WHEREの_TABLE_SUFFIXで絞り込みます。_TABLE_SUFFIXはワイルドカード部分に対応した擬似列で、このケースでは年月日が連続した数値で入っていると思ってください。 BETWEEN〜ANDと組み合わせて_TABLE_SUFFIX BETWEEN "20210801" AND "20210831"と指定することで、8月のみのデータを絞り込むことができます。
ワイルドカードと_TABLE_SUFFIXを組み合わせた絞り込みは、WHERE句ではありますが、データの読み込み量を削減できます。
RECORD型のデータをスカラーサブクエリで取り出す
Firebase Analyticsのスキーマを次のヘルプで見てみましょう。いくつかのフィールドがRECORD型として格納されている様子が分かります。

Firebase Analyticsでは、イベントに対するパラメータや、ユーザープロパティを指定することができ、それぞれevent_paramsとuser_propertiesというkey-valueのRECORD型で格納されます。
イベントは一般的にイベント名の他、パラメータとしてイベント固有の付加情報(どの画面か、対象の商品のIDは何かなど)を与えます。ユーザープロパティには、ユーザーの属性(最近購入したユーザーか、どのカテゴリを好きか)などの情報を与えます。
これらを取り出すために、スカラーサブクエリを利用するのが便利です。先ほどのPV抽出クエリでも使っていました。
CREATE OR REPLACE TABLE summary.summary_screen_view_registered_user OPTIONS() AS SELECT (SELECT value.string_value FROM UNNEST(event_params) WHERE key = "firebase_screen") AS screen_name, user_id, event_timestamp, FROM `[project].analytics_[id].events_[date]` WHERE user_id IS NOT NULL AND event_name = "screen_view"
SELECTに指定している(SELECT value.string_value〜AS screen_nameがスカラーサブクエリです。RECORD型のevent_paramsを一度展開し、必要なキーのみを取り出すことができます。取り出した値に、ASで名前をつけます。
スカラーサブクエリは複数書けるため、複数のevent_paramsやuser_propertiesを使いたい場合は、以下のようなクエリになります。
SELECT (SELECT value.string_value FROM UNNEST(event_params) WHERE key = "event_key") AS event_key, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = "int_value_key") AS int_value_key, (SELECT value.string_value FROM UNNEST(user_properties) WHERE key = "favorite_food") AS favorite_food, event_timestamp, FROM `[project].analytics_[id].events_[date]`
読みやすいクエリを書くテクニック
クエリの読みやすさは、クエリをメンテナンスする上で非常に重要です。これにもいくつかテクニックがあるので解説します。
データをWITH句で準備する
WITH句は、データの準備を行うために便利です。先ほどのイベントパラメータを取り出したクエリをWITH句で準備しておき、それに対するクエリを記述することで、イベントパラメータを利用した分析を読みやすい形で記述できます。WITH句を使わないと、クエリがネストしてしまうことになるので、影響範囲が分かりにくいクエリになってしまいます。
先ほどのスカラーサブクエリで抽出したフィールドでさらに絞り込みたい場合は、以下のように記述できます。
WITH summary AS ( SELECT (SELECT value.string_value FROM UNNEST(event_params) WHERE key = "event_key") AS event_key, (SELECT value.int_value FROM UNNEST(event_params) WHERE key = "int_value_key") AS int_value_key, (SELECT value.string_value FROM UNNEST(user_properties) WHERE key = "favorite_food") AS favorite_food, event_timestamp, FROM `[project].analytics_[id].events_[date]` ) SELECT * FROM summary WHERE event_key = "some-event-key"
WITH句クエリの可読性を高める目的であり、最適化などは行われないことに注意してください。
ユーザー定義関数として定数を定義する
クエリを書いていると、定数を定義したくなることがあるかもしれません。定数については、ユーザー定義関数として定義しておくのが一番単純です。
例えば、ある日付から1週間分のデータを分析したいときなどに、指定する日付を変更していろいろなクエリを試したいことがあると思います。この場合は、クエリの一番上に定数として、ユーザー定義関数を定義しておきます。一番上の行のみを変更することで、さまざまな日時を基準にすることができます。
例となるクエリは以下のようになります。
CREATE TEMPORARY FUNCTION start_date_str() AS ("2021-08-01"); # 開始日を指定 # 以下は編集しなくてよい CREATE TEMPORARY FUNCTION start_date() AS (FORMAT_DATE("%Y%m%d", DATE_ADD(PARSE_DATE("%Y-%m-%d", start_date_str()), INTERVAL 0 DAY))); CREATE TEMPORARY FUNCTION end_date() AS (FORMAT_DATE("%Y%m%d", DATE_ADD(PARSE_DATE("%Y-%m-%d", start_date_str()), INTERVAL 6 DAY))); SELECT event_name FROM `[project].analytics_[id].events_*` WHERE _TABLE_SUFFIX BETWEEN start_date() AND end_date()
このように定数を使って変更する場所を分かりやすくすることで、効率的にクエリの発行が行えます。
まとめ
Firebase AnalyticsをBigQueryで分析するときに使う基本的なテクニックについて説明してきました。SQLをある程度使っている方なら、今回のエントリにある内容を押さえておけば、基本的な分析については始められるようになると思います。
ここから先はSQLの知識や関数を駆使して、欲しいデータを取り出して分析を進めていくことができます。BigQueryにはさまざまな関数と演算子が用意されています。使いたい関数を次のドキュメントから探していくとよいでしょう。

また、集計関数やPIVOTを使った分析もよく行われます。PIVOTはとても強力で、SQLの表現力が一気に広がります。次の記事でも詳しく解説されています。

もし需要があれば第二弾として、実際のクエリでよく使う関数や集計方法などのテクニックについてもエントリを書いていこうと思います。他にもさまざまなテクニックがあると思いますので「こういうテクニックもあるよ!」という方がいましたらぜひ教えてください!
株式会社はてなではアプリの分析を行なってサービスを成長させていきたい方や、そうではなくともスマートフォンアプリエンジニアを募集中です!
もちろん、スマートフォンアプリエンジニア以外のエンジニアも積極採用中なので、ぜひお気軽にお声かけください!

*1:後述する_TABLE_SUFFIXの場合は、例外的にWHERE句で読み込むデータ量を制御することができます。また、クラスタ化テーブルなどでもWHERE句を工夫することで費用を抑えられます。
![]() id:kouki_dan
id:kouki_dan
斉藤 洸紀(さいとう・こうき)。2019年1月入社。マンガチームでスマートフォンアプリケーションエンジニア/テックリードを務める。
Twitter: @kouki_dan
GitHub: kouki-dan
blog: Lento con forza