
Today, we are announcing two additional capabilities of Amazon FSx for Lustre. First, a full bi-directional synchronization of your file systems with Amazon Simple Storage Service (Amazon S3), including deleted files and objects. Second, the ability to synchronize your file systems with multiple S3 buckets or prefixes.
Lustre is a large scale, distributed parallel file system powering the workloads of most of the largest supercomputers. It is popular among AWS customers for high-performance computing workloads, such as meteorology, life-science, and engineering simulations. It is also used in media and entertainment, as well as the financial services industry.
I had my first hands-on Lustre file systems when I was working for Sun Microsystems. I was a pre-sales engineer and worked on some deals to sell multimillion-dollar compute and storage infrastructure to financial services companies. Back then, having access to a Lustre file system was a luxury. It required expensive compute, storage, and network hardware. We had to wait weeks for delivery. Furthermore, it required days to install and configure a cluster.
Fast forward to 2021, I may create a petabyte-scale Lustre cluster and attach the file system to compute resources running in the AWS cloud, on-demand, and only pay for what I use. There is no need to know about Storage Area Networks (SAN), Fiber Channel (FC) fabric, and other underlying technologies.
Modern applications use different storage options for different workloads. It is common to use S3 object storage for data transformation, preparation, or import/export tasks. Other workloads may require POSIX file-systems to access the data. FSx for Lustre lets you synchronize objects stored on S3 with the Lustre file system to meet these requirements.
When you link your S3 bucket to your file system, FSx for Lustre transparently presents S3 objects as files and lets you to write results back to S3.
Full Bi-Directional Synchronization with Multiple S3 Buckets
If your workloads require a fast, POSIX-compliant file system access to your S3 buckets, then you can use FSx for Lustre to link your S3 buckets to a file system and keep data synchronized between the file system and S3 in both directions. However, until today, there were a couple limitations. First, you had to manually configure a task to export data back from FSx for Lustre to S3. Second, deleted files on S3 were not automatically deleted from the file system. And third, an FSx for Lustre file system was synchronized with one S3 bucket only. We are addressing these three challenges with this launch.
Starting today, when you configure an automatic export policy for your data repository association, files on your FSx for Lustre file system are automatically exported to your data repository on S3. Next, deleted objects on S3 are now deleted from the FSx for Lustre file system. The opposite is also available: deleting files on FSx for Lustre triggers the deletion of corresponding objects on S3. Finally, you may now synchronize your FSx for Lustre file system with multiple S3 buckets. Each bucket has a different path at the root of your Lustre file system. For example your S3 bucket logs may be mapped to /fsx/logs and your other financial_data bucket may be mapped to /fsx/finance.
These new capabilities are useful when you must concurrently process data in S3 buckets using both a file-based and an object-based workflow, as well as share results in near real time between these workflows. For example, an application that accesses file data can do so by using an FSx for Lustre file system linked to your S3 bucket, while another application running on Amazon EMR may process the same files from S3.
Moreover, you may link multiple S3 buckets or prefixes to a single FSx for Lustre file system, thereby enabling a unified view across multiple datasets. Now you can create a single FSx for Lustre file system and easily link multiple S3 data repositories (S3 buckets or prefixes). This is convenient when you use multiple S3 buckets or prefixes to organize and manage access to your data lake, access files from a public S3 bucket (such as these hundreds of public datasets) and write job outputs to a different S3 bucket, or when you want to use a larger FSx for Lustre file system linked to multiple S3 datasets to achieve greater scale-out performance.
How It Works
Let’s create an FSx for Lustre file system and attach it to an Amazon Elastic Compute Cloud (Amazon EC2) instance. I make sure that the file system and instance are in the same VPC subnet to minimize data transfer costs. The file system security group must authorize access from the instance.
I open the AWS Management Console, navigate to FSx, and select Create file system. Then, I select Amazon FSx for Lustre. I am not going through all of the options to create a file system here, you can refer to the documentation to learn how to create a file system. I make sure that Import data from and export data to S3 is selected.
 It takes a few minutes to create the file system. Once the status is
It takes a few minutes to create the file system. Once the status is  Available, I navigate to the Data repository tab, and then select Create data repository association.
Available, I navigate to the Data repository tab, and then select Create data repository association.
I choose a Data Repository path (my source S3 bucket) and a file system path (where in the file system that bucket will be imported).
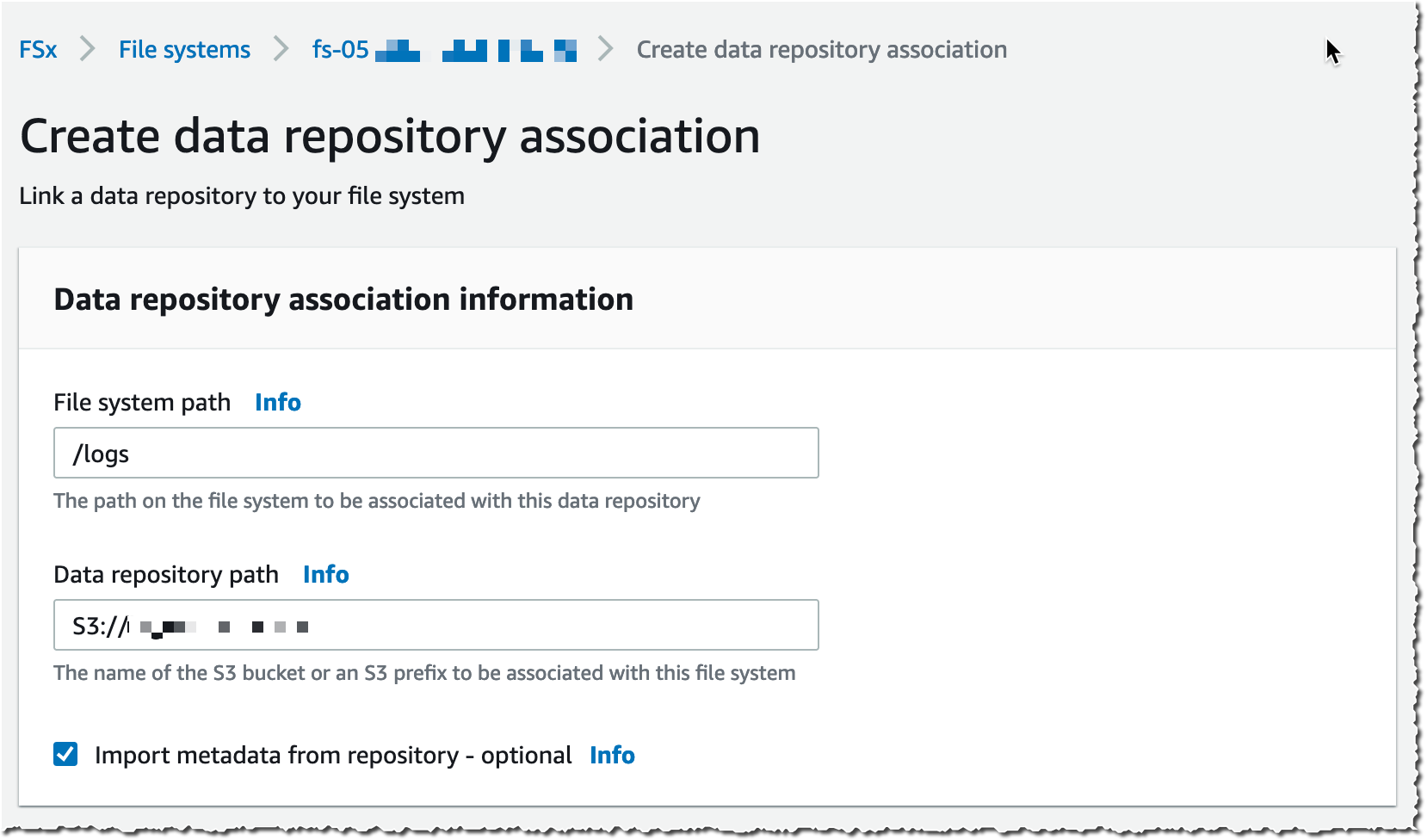
Then, I choose the Import policy and Export policy. I may synchronize the creation of file/objects, their updates, and when they are deleted. I select Create.

When I use automatic import, I also make sure to provide an S3 bucket in the same AWS Region as the FSx for Lustre cluster. FSx for Lustre supports linking to an S3 bucket in a different AWS Region for automatic export and all other capabilities.
Using the console, I see the list of Data repository associations. I wait for the import task status to become Succeeded. If I link the file system to an S3 bucket with a large number of objects, then I may choose to skip Importing metadata from repository while creating the data repository association, and then load metadata from selected prefixes in my S3 buckets that are required for my workload using an Import task.
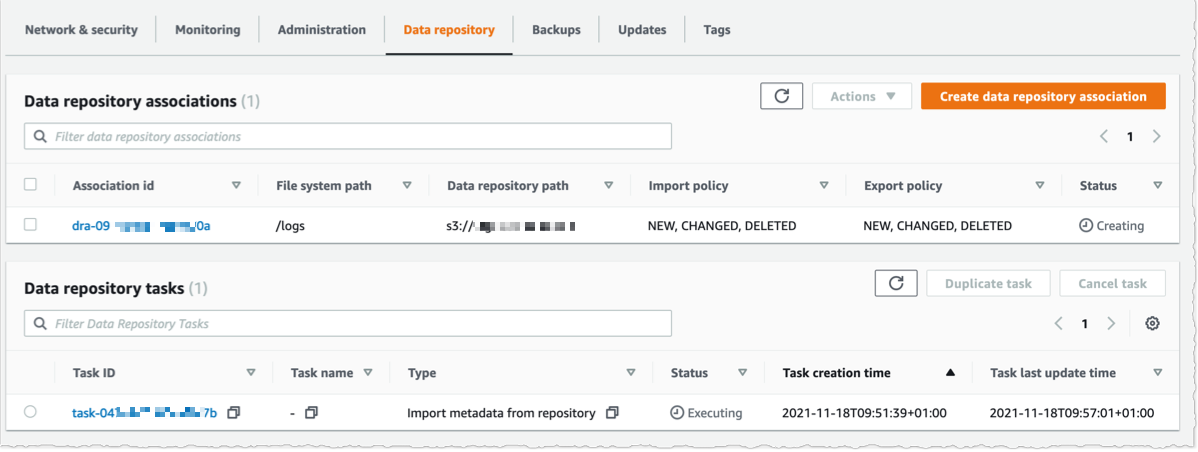
I create an EC2 instance in the same VPC subnet. Furthermore, I make sure that the FSx for Lustre cluster security group authorizes ingress traffic from the EC2 instance. I use SSH to connect to the instance, and then type the following commands (commands are prefixed with the $ sign that is part of my shell prompt).
# check kernel version, minimum version 4.14.104-95.84 is required
$ uname -r
4.14.252-195.483.amzn2.aarch64
# install lustre client
$ sudo amazon-linux-extras install -y lustre2.10
Installing lustre-client
...
Installed:
lustre-client.aarch64 0:2.10.8-5.amzn2
Complete!
# create a mount point
$ sudo mkdir /fsx
# mount the file system
$ sudo mount -t lustre -o noatime,flock fs-00...9d.fsx.us-east-1.amazonaws.com@tcp:/ny345bmv /fsx
# verify mount succeeded
$ mount
...
172.0.0.0@tcp:/ny345bmv on /fsx type lustre (rw,noatime,flock,lazystatfs)
Then, I verify that the file system contains the S3 objects, and I create a new file using the touch command.

I switch to the AWS Console, under S3 and then my bucket name, and I verify that the file has been synchronized.

Using the console, I delete the file from S3. And, unsurprisingly, after a few seconds, the file is also deleted from the FSx file system.

Pricing and Availability
These new capabilities are available at no additional cost on Amazon FSx for Lustre file systems. Automatic export and multiple repositories are only available on Persistent 2 file systems in US East (N. Virginia), US East (Ohio), US West (Oregon), Canada (Central), Asia Pacific (Tokyo), Europe (Frankfurt), and Europe (Ireland). Automatic import with support for deleted and moved objects in S3 is available on file systems created after July 23, 2020 in all regions where FSx for Lustre is available.
You can configure your file system to automatically import S3 updates by using the AWS Management Console, the AWS Command Line Interface (CLI), and AWS SDKs.
Learn more about using S3 data repositories with Amazon FSx for Lustre file systems.
One More Thing
One more thing while you are reading. Today, we also launched the next generation of FSx for Lustre file systems. FSx for Lustre next-gen file systems are built on AWS Graviton processors. They are designed to provide you with up to 5x higher throughput per terabyte (up to 1 GB/s per terabyte) and reduce your cost of throughput by up to 60% as compared to previous generation file systems. Give it a try today!
PS : my colleague Michael recorded a demo video to show you the enhanced S3 integration for FSx for Lustre in action. Check it out today.